Bayes 分类器
本质上是对样本在每个类内的分布做了假设。
下面不妨假设:
- 二分类 ω1,ω2;
- 两类 类内 均满足正态分布,即 x∣ω1∼N1(μ1,σ1),x∣ω2∼N2(μ2,σ2).
可以理解为确定下图中的分界线 x0.
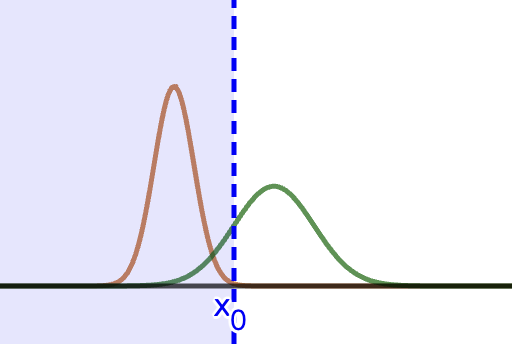
根据假设,我们可以立刻确定,某个样本 x 在类内的概率 P(x∣ω1),P(x∣ω2) 是正态的(参数后面才确定)。
进一步,如果训练集已知(这个总不能未知吧…),还可以求出两类分别的均值和方差(作为上面正态分布的参数),以及样本空间中两类的概率 P(ω1),P(ω2)(通过训练集中的频率确定)。
最小错误率
很简单的。最小化错误概率。
假设采样为 x,分别将其分类为 ω1,ω2 的正确概率为
P(ω1∣x)P(ω2∣x)=P(x)P(x∣ω1)⋅P(ω1)=P(x)P(x∣ω2)⋅P(ω2)
取较大的即可。特别地,因为 P(x) 公共,且有的时候概率会比较小,实践上通常比较 logP(x∣ω∘)+logP(ω∘).
对。交叉熵的味道来了。
最小风险
然而假阳性和漏判的权重通常不同。假设将类 j 分类为类 i 的风险(权重)为 L(i∣j),那么最终比较的量就不是 P(ω∘∣x) 而是对所有的风险求和,即
kargmini∑L(k∣i)P(ωi∣x)
这样就相当于最小化了风险。
最小最大
问题是,训练集常常不是对整个空间的均匀采样。因此频率有的时候不能作为 P(ω∘). 有没有不依赖样本分布的分类方案?
参考 min-max 搜索,直接让对手(大自然?)生成一个最史的分布 D,然后最大化这个时候的正确率(或者最小化风险)。
… 算不动了 摸鱼。
正态特例、错误率和其他
正态是一个“椭圆形的”分布。因此 σ 相同的时候分界线就是中垂线。
错误率上限可以计算。